# Classifying encyclopedia articles
This repository contains the code developed for classifying French encyclopedia articles as part of the [GEODE](https://geode-project.github.io/) project.
<!--
## Utilisation
Ce dépôt est un paquet python pouvant être installé avec
[`pip`](https://pypi.org/) ainsi qu'avec [`guix`](https://guix.gnu.org/). À
partir d'une copie, depuis ce dossier, il est possible d'obtenir un
environnement dans lequel `pyedda` est installé et utilisable dans un shell à
l'aide des commandes suivantes:
### Pip
```sh
pip install -e .
```
### Guix
```sh
guix shell python -f guix.scm
```
-->
## Overview
This git repository contains the code developed for a comparative study of supervised classification approaches applied to the automatic classification of encyclopedia articles written in French.
Our dataset is composed of 17 volumes of text from the *Encyclopédie* by Diderot and d'Alembert (1751-72) including about 70,000 articles.
We combine text vectorization (bag-of-words and word embeddings) with machine learning methods, deep learning, and transformer architectures.
In addition evaluating these approaches, we review the classification predictions using a variety of quantitative and qualitative methods.
The best model obtains 86% as an average F-score for 38 classes.
Using network analysis we highlight the difficulty of classifying semantically close classes. We also introduce examples of opportunities for qualitative evaluation of "misclassifications" in order to understand the relationship between content and different ways of ordering knowledge.
## Experiments
Our experiments compare approaches to classifying *EDdA* articles using vectorization and supervised classification. We test the following combinations:
1. Bag-of-words vectorization and classic ML algorithms (Naive Bayes, Logistic Regression, Random forest, SVM and SGD);
2. Vectorization using static word embeddings (Doc2Vec) and classic ML algorithms (Logistic regression, Random Forest, SVM et SGD);
3. Vectorization using static word embeddings (FastText[fr]) and deep learning algorithms (CNN and BiLSTM);
4. An *end-to-end* approach using pre-trained contextual language models (BERT, CamemBERT) with fine-tuning to adapt the model for our task.
## Results
All the results (measured with precision, recall and F-score) are in the [reports](./reports) directory. Some tables and figures are listed below:
### Mean F-scores for different models for the test set with a sample of a maximum of 500 articles (1), 1 500 (2) and no limit (3).
| Classifier | Vectorizer | | F-score | |
| ------------------------------- | ------------- | ----- | ----- | ----- |
| | | (1) | (2) | (3) |
| Naive Bayes | Bag of Words | 0.63 | 0.71 | 0.70 |
| | TF-IDF | 0.74 | 0.69 | 0.44 |
| Logistic Regression | Bag of Words | 0.74 | 0.77 | 0.79 |
| | TF-IDF | 0.77 | 0.79 | 0.81 |
| | Doc2Vec | 0.64 | 0.69 | 0.77 |
| Random Forest | Bag of Words | 0.57 | 0.54 | 0.16 |
| | TF-IDF | 0.55 | 0.53 | 0.16 |
| | Doc2Vec | 0.63 | 0.66 | 0.60 |
| SGD | Bag of Words | 0.70 | 0.73 | 0.75 |
| | TF-IDF | 0.77 | 0.81 | 0.81 |
| | Doc2Vec | 0.68 | 0.72 | 0.76 |
| SVM | Bag of Words | 0.71 | 0.75 | 0.78 |
| | TF-IDF | 0.77 | 0.80 | 0.81 |
| | Doc2Vec | 0.68 | 0.74 | 0.78 |
| CNN | FastText | 0.65 | 0.72 | 0.74 |
| BiLSTM | FastText | 0.69 | 0.79 | 0.80 |
| BERT Multilingual (fine-tuning) | - | 0.81 | 0.85 | 0.86 |
| CamemBERT (fine-tuning) | - | 0.78 | 0.83 | 0.86 |
### F-scores for classes on the test set obtained with SGD + TF-IDF (1), BiLSTM + FastText (2) and BERT Multilingual (3).
| Ensemble de domaines | Support | (1) | (2) | (3) | Ensemble de domaines | Support | (1) | (2) | (3) |
| ----------------------- | ------- | ---- | ---- | ---- | -------------------- | ------- | ---- | ---- | ---- |
| Géographie | 2 621 | 0.96 | 0.98 | 0.99 | Chasse | 116 | 0.87 | 0.87 | 0.92 |
| Droit - Jurisprudence | 1 284 | 0.88 | 0.90 | 0.93 | Arts et métiers | 112 | 0.15 | 0.27 | 0.36 |
| Métiers | 1 051 | 0.79 | 0.76 | 0.81 | Blason | 108 | 0.87 | 0.86 | 0.89 |
| Histoire naturelle | 963 | 0.90 | 0.87 | 0.93 | Maréchage [\ldots] | 105 | 0.83 | 0.86 | 0.90 |
| Histoire | 616 | 0.64 | 0.64 | 0.75 | Chimie | 104 | 0.70 | 0.58 | 0.77 |
| Médecine [\ldots] | 455 | 0.83 | 0.80 | 0.86 | Philosophie | 94 | 0.75 | 0.49 | 0.72 |
| Grammaire | 452 | 0.58 | 0.54 | 0.71 | Beaux-arts | 86 | 0.70 | 0.62 | 0.82 |
| Marine | 415 | 0.83 | 0.86 | 0.88 | Pharmacie | 65 | 0.53 | 0.38 | 0.63 |
| Commerce | 376 | 0.71 | 0.69 | 0.74 | Monnaie | 63 | 0.63 | 0.50 | 0.72 |
| Religion | 328 | 0.78 | 0.77 | 0.84 | Jeu | 56 | 0.84 | 0.74 | 0.85 |
| Architecture | 278 | 0.79 | 0.74 | 0.80 | Pêche | 42 | 0.85 | 0.84 | 0.85 |
| Antiquité | 272 | 0.66 | 0.68 | 0.74 | Mesure | 37 | 0.35 | 0.10 | 0.56 |
| Physique | 265 | 0.75 | 0.76 | 0.82 | Economie domestique | 27 | 0.41 | 0.48 | 0.44 |
| Militaire [\ldots] | 258 | 0.83 | 0.82 | 0.88 | Caractères | 23 | 0.61 | 0.08 | 0.46 |
| Agriculture [\ldots] | 233 | 0.68 | 0.58 | 0.71 | Médailles | 23 | 0.77 | 0.70 | 0.86 |
| Anatomie | 215 | 0.89 | 0.84 | 0.90 | Politique | 23 | 0.15 | 0.22 | 0.53 |
| Belles-lettres - Poésie | 206 | 0.58 | 0.41 | 0.70 | Minéralogie | 22 | 0.38 | 0.39 | 0.70 |
| Mathématiques | 140 | 0.82 | 0.85 | 0.89 | Superstition | 22 | 0.72 | 0.48 | 0.41 |
| Musique | 137 | 0.87 | 0.83 | 0.88 | Spectacle | 9 | 0.33 | 0.46 | 0.61 |
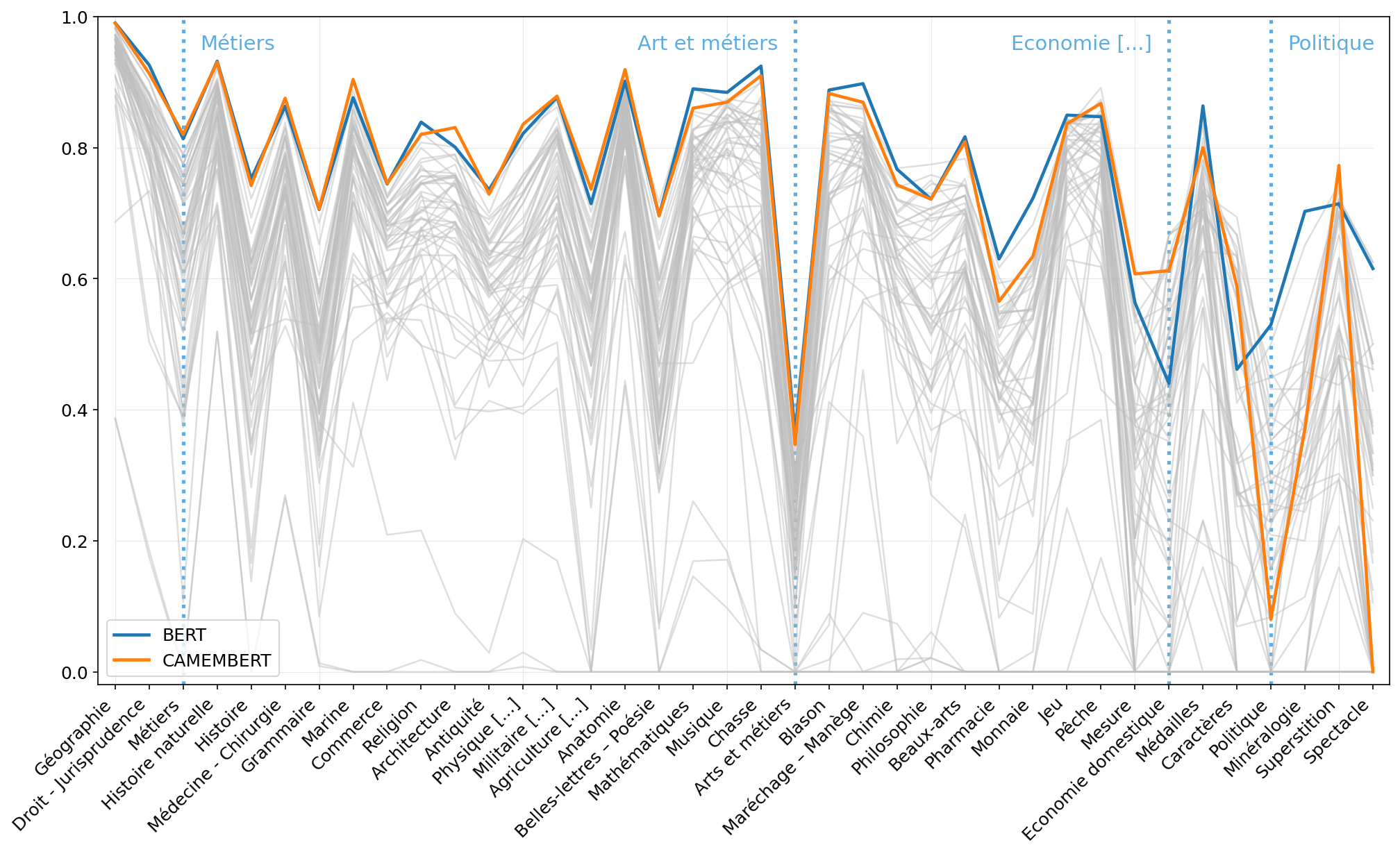
### F-scores obtained with BERT Multilingual and CamemBERT for each class
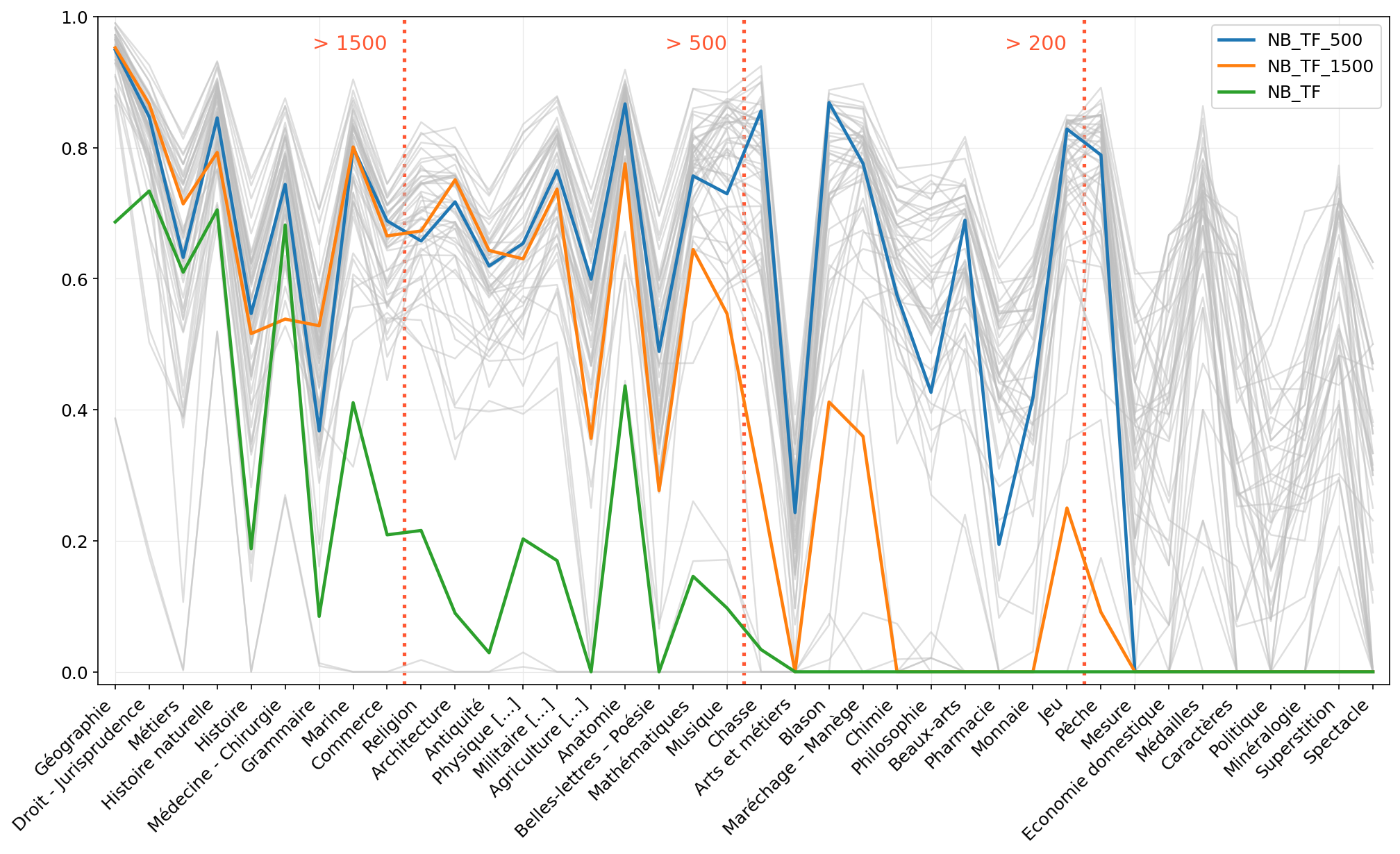
### F-scores obtained with Naive Bayes + TF-IDF on each class with three different sampling.
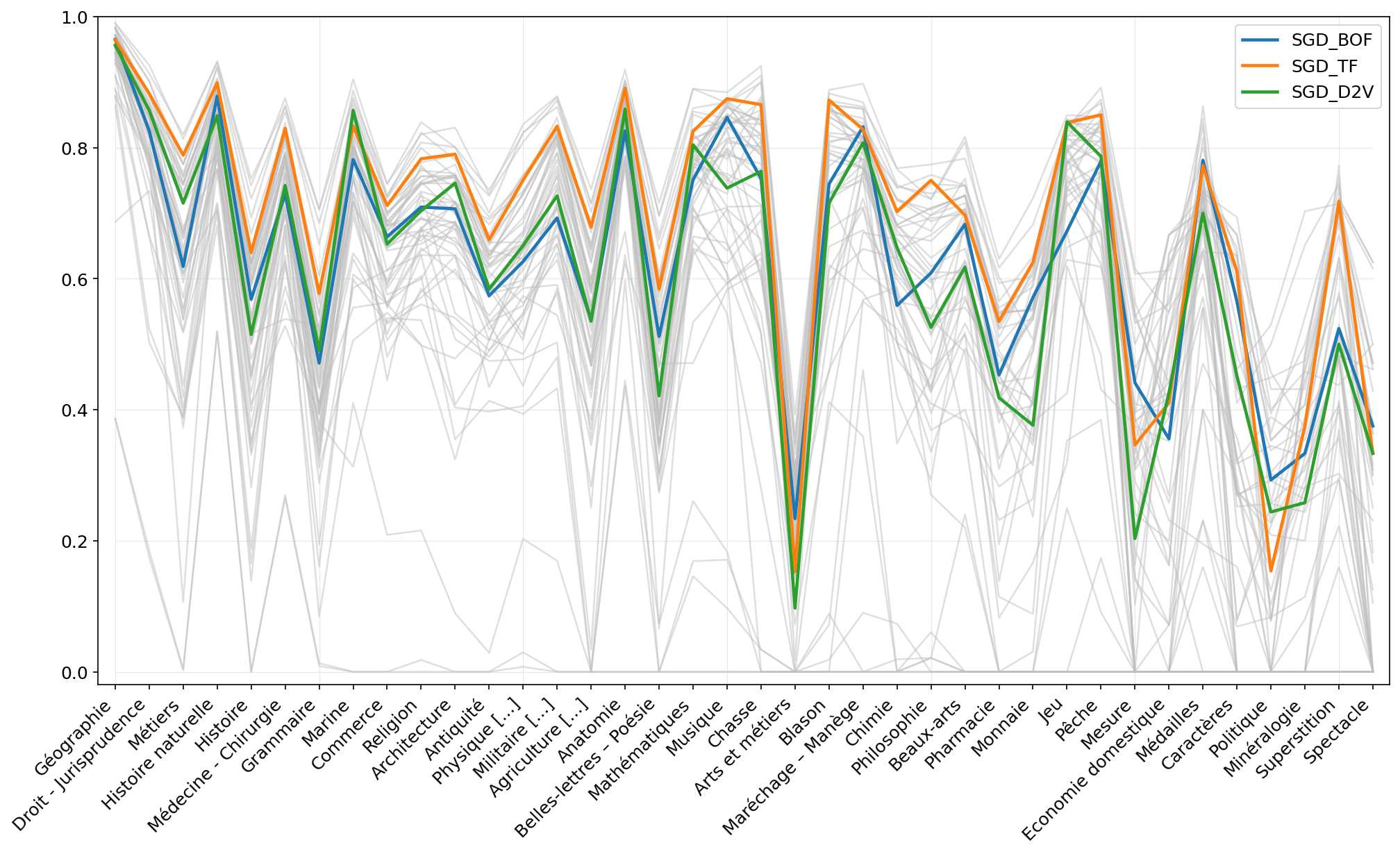
### F-scores obtained with SGD on each class with three different vectorizers without sampling.
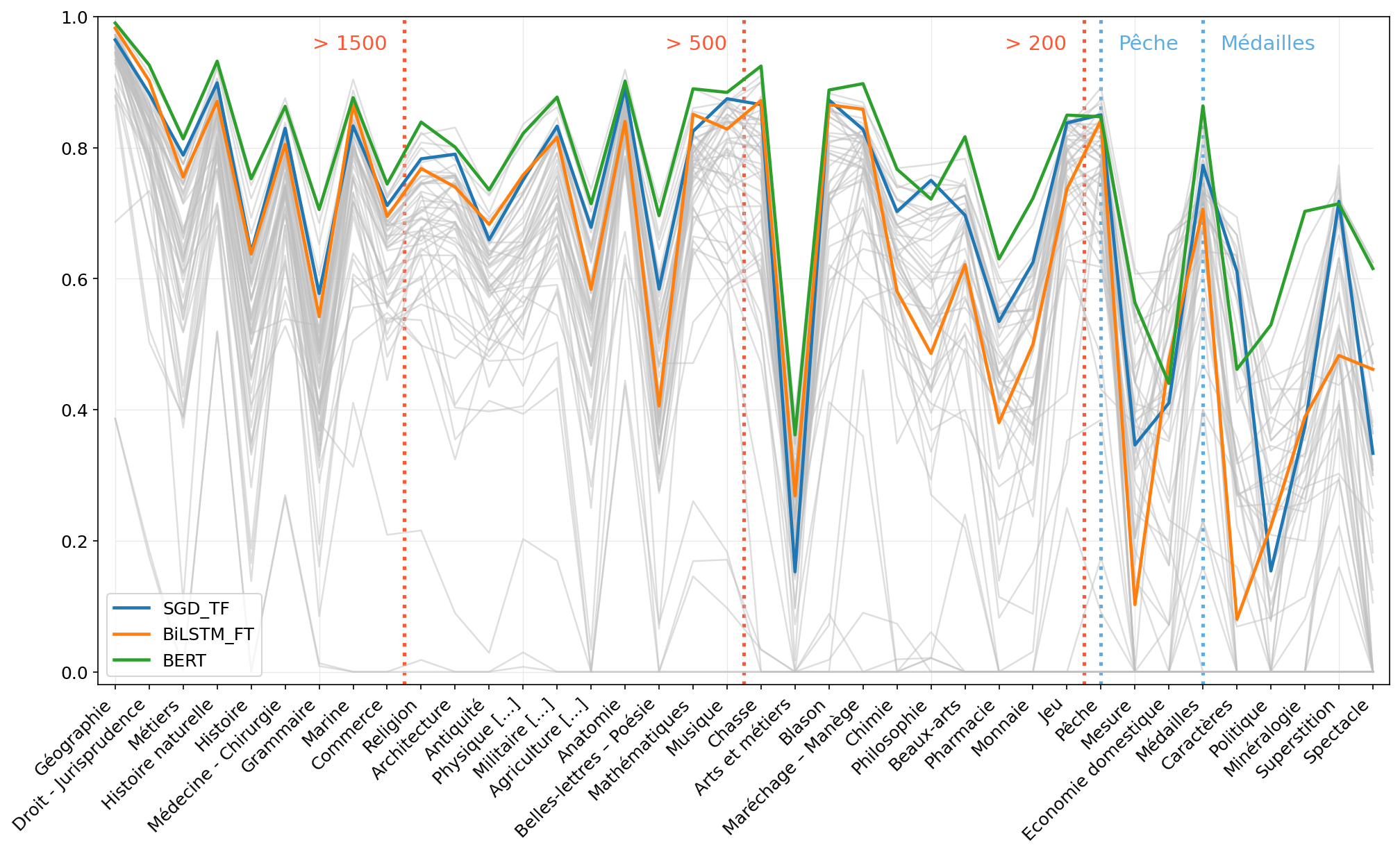
### F-scores for classes on the test set obtained with SGD + TF-IDF, BiLSTM + FastText and BERT Multilingual.
### Confusion matrix for SGD+TF-IDF
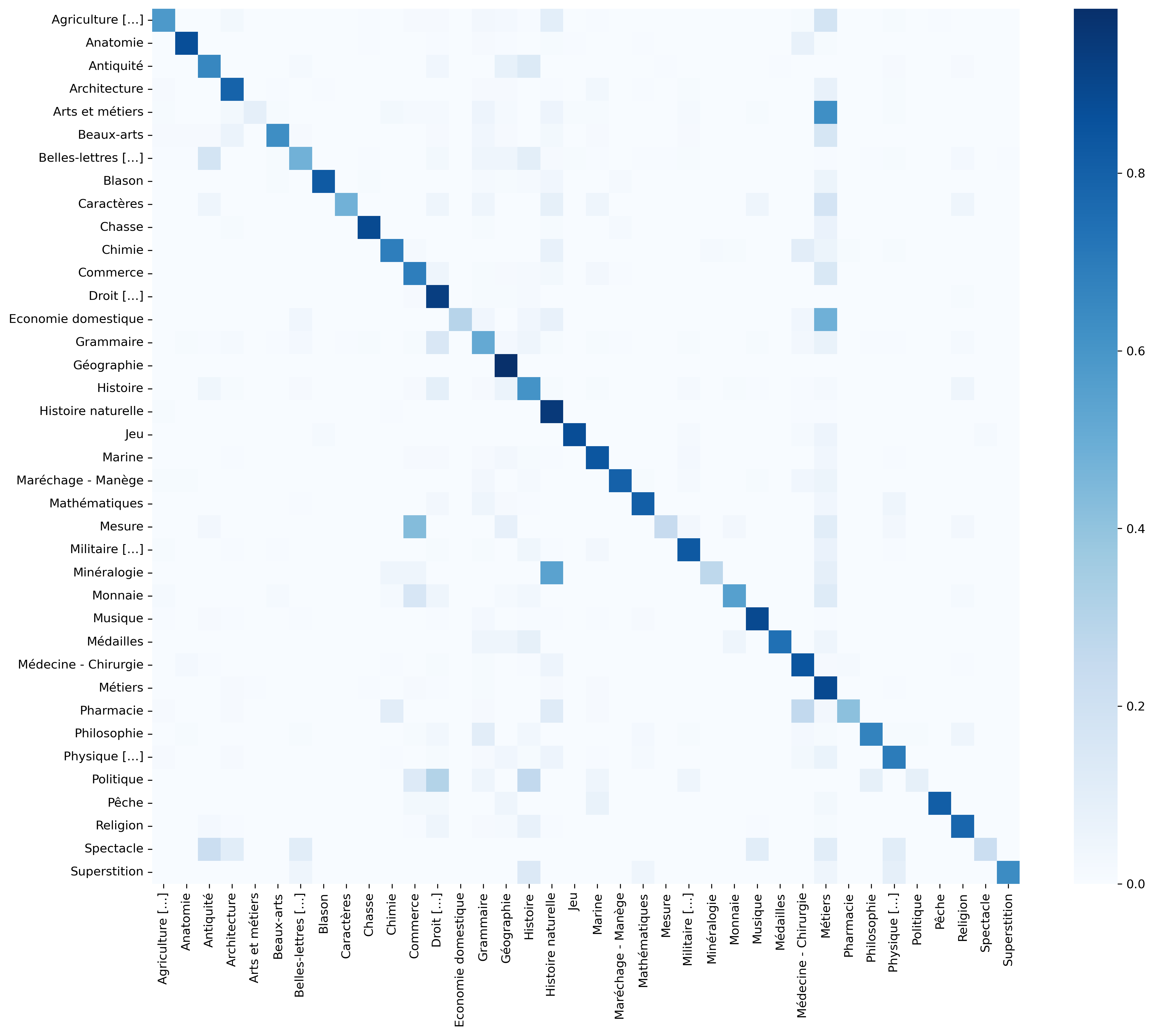
This confusion matrix presents the results for the SGD+TF-IDF model on the test set. We see that most articles in the classes *Arts et métiers* and *Economie domestique* (Domestic economy) were classified as *Métiers*. In the same manner *Mesure* (Measurement), *Minéralogie* (Mineralology), *Pharmacie* (Pharmacy) and *Politique* (Politics) were confused with *Commerce*, *Histoire naturelle* (Natural history), *Médecine - Chirurgie* (Medicine - Surgery) and *Droit - Jurisprudence* (Law), respectively. The semantic similarity between these classes illustrates the difficulty a model has when choosing a “best match.” The results confirm that when there is great semantic similarity, the model chooses the best represented class in the dataset, thereby privileging certain ENCCRE domains that contain more articles.
## Cite our work
Moncla, L., Chabane, K., et Brenon, A. (2022). Classification automatique
d’articles encyclopédiques. *Conférence francophone sur l’Extraction et la
Gestion des Connaissances ([EGC](https://egc2022.univ-tours.fr/))*. Blois, France. [https://hal.archives-ouvertes.fr/hal-03481219v1](https://hal.archives-ouvertes.fr/hal-03481219v1)
## Ackowledgements
Data courtesy the ARTFL Encyclopédie Project, University of Chicago.
This work was supported by the [ASLAN project](https://aslan.universite-lyon.fr/) (ANR-10-LABX-0081) of Université de Lyon, within the program « Investissements d’Avenir » operated by the French National Research Agency (ANR).