# PyEDdA Ce dépôt contient le code réalisé dans le cadre du projet [GEODE](https://geode-project.github.io/) par **Khaled Chabane**, **Ludovic Moncla** et **Alice Brenon**. Il contient le code développé à l'origine pour l'article "*Classification automatique d'articles encyclopédiques*" ([https://hal.archives-ouvertes.fr/hal-03481219v1](https://hal.archives-ouvertes.fr/hal-03481219v1)) présenté lors de la conférence [EGC 2022](https://egc2022.univ-tours.fr/). ## Utilisation Ce dépôt est un paquet python pouvant être installé avec [`pip`](https://pypi.org/) ainsi qu'avec [`guix`](https://guix.gnu.org/). À partir d'une copie, depuis ce dossier, il est possible d'obtenir un environnement dans lequel `pyedda` est installé et utilisable dans un shell à l'aide des commandes suivantes: ### Pip ```sh pip install -e . ``` ### Guix ```sh guix shell python -f guix.scm ``` ## Présentation Ce dépôt contient le code développée pour une étude comparative de différentes approches de classification supervisée appliquées à la classification automatique d’articles encyclopédiques. Notre corpus d’apprentissage est constitué des 17 volumes de texte de l’Encyclopédie de Diderot et d’Alembert (1751-1772) représentant un total d’environ 70 000 articles. Nous avons expérimenté différentes approches de vectorisation de textes (sac de mots et plongement de mots) combinées à des méthodes d’apprentissage automatique classiques, d’apprentissage profond et des architectures BERT. En plus de la comparaison de ces différentes approches, notre objectif est d’identifier de manière automatique les domaines des articles non classés de l’Encyclopédie (environ 2 400 articles). ## Méthodes testées Nos expérimentations concernent l’étude de différentes approches de classification comprenant deux étapes principales : la vectorisation et la classification supervisée. Nous avons testé et comparé les différentes combinaisons suivantes : 1. vectorisation en sac de mots et apprentissage automatique classique (Naive Bayes, Logistic regression, Random Forest, SVM et SGD) ; 2. vectorisation en plongement de mots statiques (Doc2Vec) et apprentissage automatique classique (Logistic regression, Random Forest, SVM et SGD) ; 3. vectorisation en plongement de mots statiques (FastText) et apprentissage profond (CNN et LSTM) ; 4. approche *end-to-end* utilisant un modèle de langue pré-entraîné (BERT,CamemBERT) et une technique de *fine-tuning* pour adapter le modèle sur notre tâche de classification. ## Résultats ### F-mesures moyennes des différents modèles pour les jeux de validation et de test avec un échantillonnage max de 500 (1) et 1 500 (2) articles par classe et sans échantillonnage (3). | Classifieur | Vectorisation | | Test | | | ------------------------------- | ------------- | ---- | ---- | ---- | | | | (1) | (2) | (3) | | Naive Bayes | Bag of Words | 0.72 | 0.68 | 0.61 | | | TF-IDF | 0.74 | 0.59 | 0.37 | | Logistic Regression | Bag of Words | 0.85 | 0.85 | 0.86 | | | TF-IDF | 0.88 | 0.88 | 0.88 | | | Doc2Vec | 0.39 | 0.39 | 0.44 | | Random Forest | Bag of Words | 0.50 | 0.49 | 0.17 | | | TF-IDF | 0.48 | 0.48 | 0.16 | | | Doc2Vec | 0.28 | 0.29 | 0.37 | | SGD | Bag of Words | 0.85 | 0.86 | 0.86 | | | TF-IDF | 0.88 | 0.88 | 0.88 | | | Doc2Vec | 0.43 | 0.42 | 0.44 | | SVM | Bag of Words | 0.85 | 0.85 | 0.86 | | | TF-IDF | 0.86 | 0.86 | 0.87 | | | Doc2Vec | 0.32 | 0.32 | 0.43 | | CNN | FastText | 0.04 | 0.05 | 0.09 | | LSTM | FastText | 0.10 | 0.10 | 0.12 | | BERT Multilingual (fine-tuning) | - | 0.84 | 0.88 | 0.89 | | CamemBERT (fine-tuning) | - | 0.82 | 0.86 | 0.88 | ### F-mesures obtenues par ensemble de domaines avec les approches SGD + TF-IDF (1), LSTM + FastText (2) et BERT (3) sans échantillonnage et sur le jeu de test. | Ensemble de domaines | Support | (1) | (2) | (3) | Ensemble de domaines | Support | (1) | (2) | (3) | | ----------------------- | ------- | ---- | ---- | ---- | -------------------- | ------- | ---- | ---- | ---- | | Géographie | 2 870 | 0.98 | 0.22 | 0.99 | Arts et métiers | 132 | 0.45 | 0.00 | 0.51 | | Droit - Jurisprudence | 1 452 | 0.92 | 0.39 | 0.94 | Blason | 126 | 0.93 | 0.00 | 0.93 | | Métiers | 1 220 | 0.87 | 0.07 | 0.89 | Chasse | 124 | 0.92 | 0.01 | 0.92 | | Histoire naturelle | 1 130 | 0.92 | 0.06 | 0.95 | Maréchage [\ldots] | 118 | 0.90 | 0.00 | 0.88 | | Histoire | 726 | 0.76 | 0.08 | 0.80 | Chimie | 115 | 0.75 | 0.02 | 0.72 | | Grammaire | 575 | 0.77 | 0.08 | 0.81 | Philosophie | 115 | 0.75 | 0.01 | 0.69 | | Médecine [\ldots] | 535 | 0.87 | 0.07 | 0.87 | Beaux-arts | 103 | 0.86 | 0.00 | 0.84 | | Marine | 454 | 0.93 | 0.03 | 0.94 | Monnaie | 74 | 0.81 | 0.00 | 0.79 | | Commerce | 437 | 0.85 | 0.04 | 0.85 | Pharmacie | 75 | 0.65 | 0.00 | 0.58 | | Religion | 389 | 0.89 | 0.02 | 0.90 | Jeu | 67 | 0.85 | 0.00 | 0.87 | | Architecture | 326 | 0.88 | 0.01 | 0.88 | Pêche | 48 | 0.93 | 0.00 | 0.90 | | Antiquité | 321 | 0.80 | 0.01 | 0.82 | Mesure | 43 | 0.65 | 0.00 | 0.74 | | Physique | 309 | 0.85 | 0.04 | 0.86 | Economie domestique | 31 | 0.75 | 0.00 | 0.58 | | Militaire [\ldots] | 304 | 0.92 | 0.01 | 0.92 | Médailles | 28 | 0.84 | 0.00 | 0.79 | | Agriculture [\ldots] | 259 | 0.80 | 0.04 | 0.80 | Caractères | 27 | 0.67 | 0.00 | 0.51 | | Belles-lettres - Poésie | 246 | 0.75 | 0.01 | 0.74 | Politique | 27 | 0.31 | 0.00 | 0.00 | | Anatomie | 245 | 0.92 | 0.02 | 0.91 | Minéralogie | 26 | 0.68 | 0.00 | 0.65 | | Mathématiques | 164 | 0.88 | 0.00 | 0.89 | Superstition | 26 | 0.81 | 0.00 | 0.73 | | Musique | 163 | 0.94 | 0.01 | 0.94 | Spectacle | 11 | 0.17 | 0.00 | 0.00 | ### Matrice de confusion obtenue avec l’approche SGD+TF-IDF sur le jeu de test 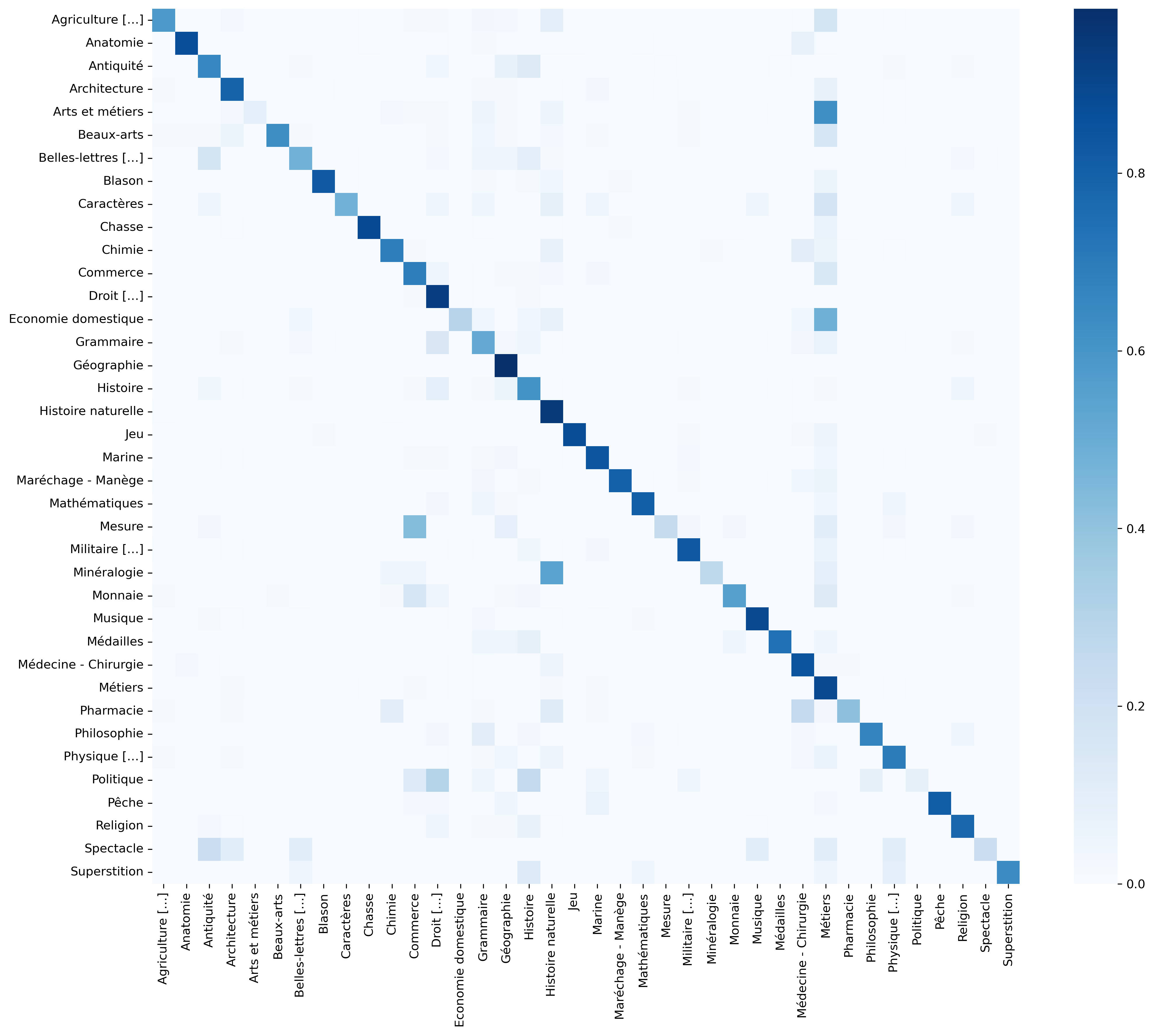 Cette figure présente la matrice de confusion obtenue avec la méthode SGD+TF-IDF sur le jeu de test. On peut voir qu’un grand nombre d’articles des classes *Arts et métiers* et *Economie domestique* a été classé dans la classe *Métiers*, de la même manière les classes *Mesure*, *Miné- ralogie*, *Pharmacie* et *Politique* sont souvent confondues avec les classes *Commerce*, *Histoire naturelle*, *Médecine - Chirurgie* et *Droit - Jurisprudence*, respectivement. Les proximités sé- mantiques entre ces classes montrent bien la difficulté pour les modèles de choisir entre l’une ou l’autre et les résultats confirment qu’en cas de trop grande proximité les modèles choisissent la classe la plus représentée dans le jeu de données. ## Citation Moncla, L., Chabane, K., et Brenon, A. (2022). Classification automatique d’articles encyclopédiques. *Conférence francophone sur l’Extraction et la Gestion des Connaissances (EGC)*. Blois, France. ## Remerciements Les auteurs remercient le [LABEX ASLAN](https://aslan.universite-lyon.fr/) (ANR-10-LABX-0081) de l'Université de Lyon pour son soutien financier dans le cadre du programme français "Investissements d'Avenir" géré par l'Agence Nationale de la Recherche (ANR).