@@ -44,25 +44,15 @@ Use the built-in continuous integration in GitLab.
***
# Editing this README
When you're ready to make this README your own, just edit this file and use the handy template below (or feel free to structure it however you want - this is just a starting point!). Thank you to [makeareadme.com](https://www.makeareadme.com/) for this template.
## Suggestions for a good README
Every project is different, so consider which of these sections apply to yours. The sections used in the template are suggestions for most open source projects. Also keep in mind that while a README can be too long and detailed, too long is better than too short. If you think your README is too long, consider utilizing another form of documentation rather than cutting out information.
## Name
Choose a self-explaining name for your project.
**DeepDense: Enabling Node Embedding to DenseSubgraph Mining**
## Description
Let people know what your project can do specifically. Provide context and add a link to any reference visitors might be unfamiliar with. A list of Features or a Background subsection can also be added here. If there are alternatives to your project, this is a good place to list differentiating factors.
## Badges
On some READMEs, you may see small images that convey metadata, such as whether or not all the tests are passing for the project. You can use Shields to add some to your README. Many services also have instructions for adding a badge.
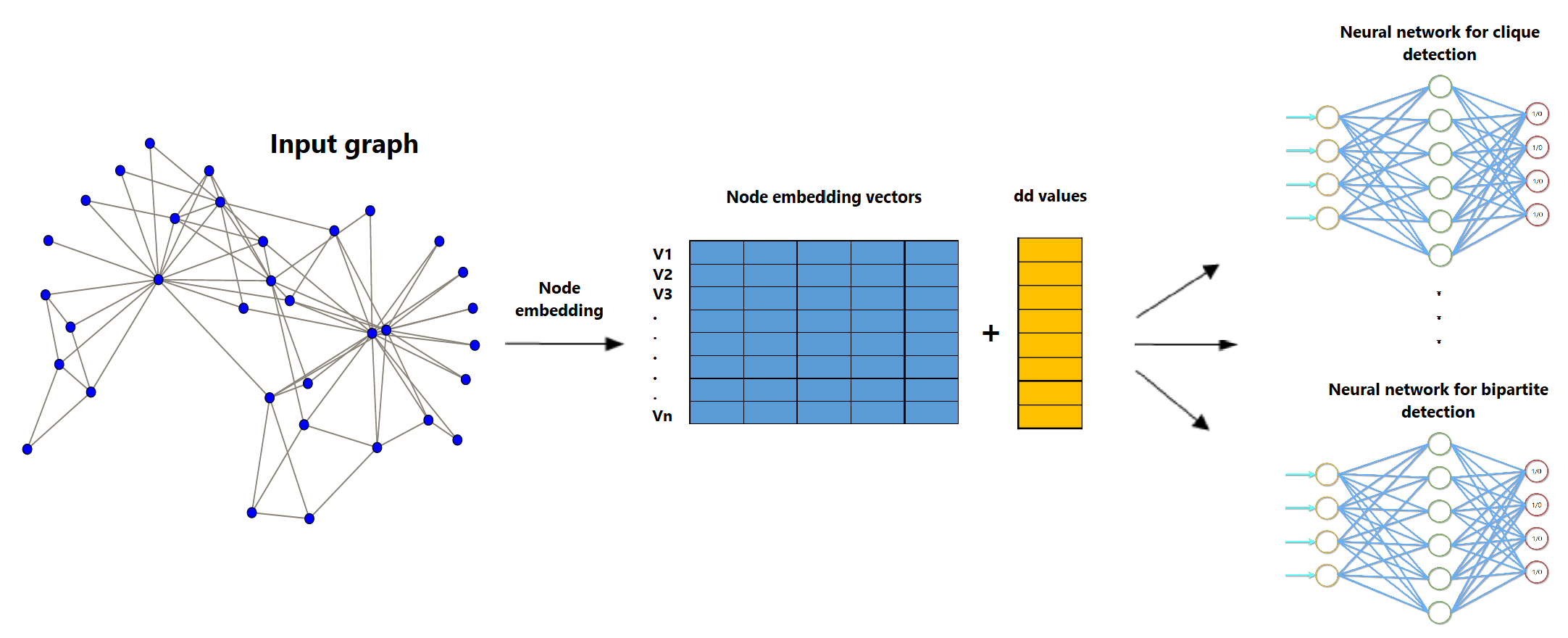
Dense subgraphs convey important information and insights about a graph structure. This explains why dense subgraph mining is a problem of key interest that arises in several tasks and applications such as graph visualization, graph summarization, graph clustering, and complex network analysis. It is a hard problem that has been intensively addressed in the data mining community.
In this paper, we propose a deep learning approach that enumerates almost all occurrences of dense subgraphs in a graph without any constraints or limitations on their size. More precisely, we enrich exiting structural node embedding with extra information computed on node neighborhoods to capture their belonging to specific types of dense subgraphs, leading to more meaningful embedding. We evaluate our approach on several datasets to attest its efficiency on two main applications, namely, graph summarization and graph clustering.
## Visuals
Depending on what you are making, it can be a good idea to include screenshots or even a video (you'll frequently see GIFs rather than actual videos). Tools like ttygif can help, but check out Asciinema for a more sophisticated method.

## Installation
Within a particular ecosystem, there may be a common way of installing things, such as using Yarn, NuGet, or Homebrew. However, consider the possibility that whoever is reading your README is a novice and would like more guidance. Listing specific steps helps remove ambiguity and gets people to using your project as quickly as possible. If it only runs in a specific context like a particular programming language version or operating system or has dependencies that have to be installed manually, also add a Requirements subsection.

{kind=link}